
Following my post about Agile methodologies in museums, I wandered (as one does on the Internet) to adjacent topics. According to my Scrum Master brother, one of the anti-patterns in museums that makes Agile implementation difficult to fathom is the specialization of roles. Whereas software developers are expected to be familiar with all the layers of code that make up modern software “the full stack”, museum expertise is pretty highly differentiated. Curatorial is separate from interpretation which is separate from collections. It allows for great specialization, but makes it harder to see how all the pieces of museum work can and should fit together to make for great visitor engagement. It makes it hard to even see the digital manifestations of our work as belonging to a single stack, which makes it very hard to develop digital experiences that can take advantage of all the affordances the modern internet provides. It’s a classic wicked problem, where even trying to outline the contours of the issue is hard and changeable. But, those are the problems most worth poking at, right? So I started collecting stacks and looking for similarities, and potential applications.
So I tweeted my question into the ether,
and lo! Answers returned.
Other people are wrestling with the same or similar issues. We decided to have a higher-bandwidth conversation than Twitter allows and scheduled a time to hang out and talk. I had a great lunchtime chat the other day with colleagues in Pittsburgh (Jeff Inscho @staticmade), St. Paul (Bryan Kennedy @xbryanx), and San Diego (Chad Weinard @caw_) about the idea of the museum full stack and how and why to build it.
Part of the problem I think, is that the full stack is hard to comprehend and traditionally hasn’t even been thought of (outside of IT circles) as a data ecosystem, but rather as a series of disconnected systems, owned and operated by separate departments, with parochial concerns. Certainly my own experience with developing digital experiences reflects that. This is also partly an historical artifact. A lot of these systems probably can trace their lineages back to when they were separate, discrete systems that possessed little or no ability to interoperate. The Internet has wrecked that isolation, as it has so many other things. Time to build a new perception of the museum data ecosystem and say goodbye to the days when IT owned this piece, and that piece was Collections’ worry. The reality is much more interconnected.
Cooper Hewitt’s stack
A lot of the impetus for me starting this conversation was a post by Seb Chan about the Cooper Hewitt’ API, their stack and it’s centrality to their vision. It starts with the museum’s two “sources of truth”, the repositories of the two kinds of data that the Cooper Hewitt relies on; data about objects, and data about visitors. Go read the whole thing. It’s worth it. I immediately resonated with the graphic on several levels. We use some of the same systems, and have been wrestling with the same kinds of ideas around providing visitors with personalized experiences. I’m particularly interested in representing the abundance of information in collections, and it’s hard to do that in the dominant paradigm of “search”.
“Decades of digitisation have made a wealth of digital cultural material available online. Yet search — the dominant interface to these collections — is incapable of representing this abundance. Search is ungenerous: it withholds information, and demands a query.”
Mitchell Whitelaw
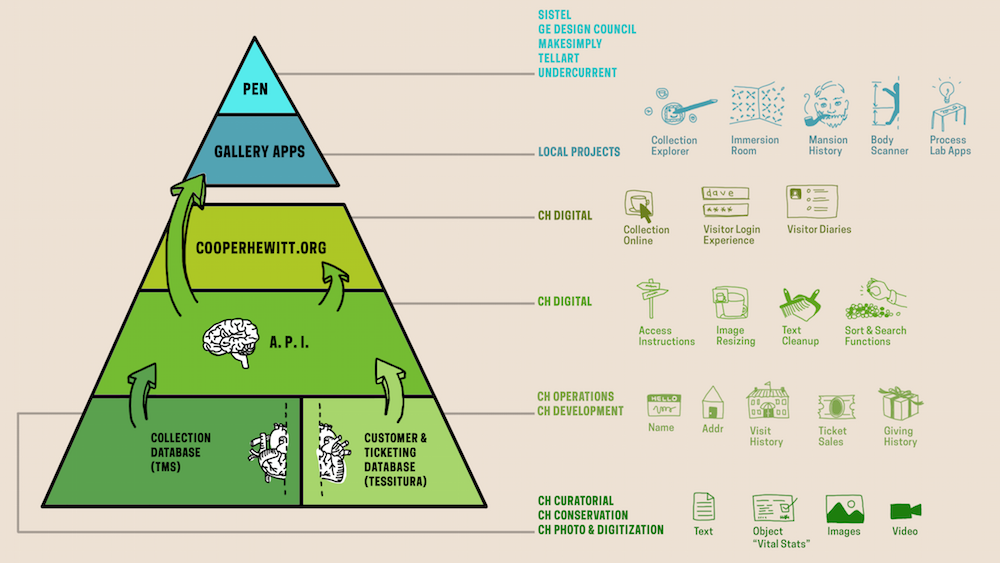
Cooper Hewitt’s approach of using the full stack approach makes it possible for them to provide visitors with multiple entry points into the collection through interactive experiences, what Mitchell Whitelaw would call more “generous interfaces”. I find it hard to perceive any other way to do that without stepping back and looking at the full stack, seeing the forest through the trees as it were.
Here are a few of the other things that came up in our chat.
Objects, Experiences, People
Cooper Hewitt’s stack is a great model because it’s suitably specific. Their model would not likely be your model or anybody else’s, for that matter. The systems they rely on, and the staff expertise they bring to bear are unique. So their “two sources of truth” might not be yours. As Bryan pointed at, at his museum, Science Museum of Minnesota, they are as focused on the experiences they build as they are on the objects they use to populate some of those experiences. They are fundamental to the museum’s operation and incorporate content and ideas that don’t neatly fit in either source of truth. They’re not about objects, per se. For them, the experience is a truth that needs its own source. Cooper Hewitt doesn’t, but the Rijksmuseum might classify visitors’ digital creations as a separate source of truth, related to, yet distinct from the CMS or CRM systems. You get the idea?… At its most basic, atomic level, we want to be able to store, retrieve, and connect people, objects, and experiences.
What I find powerful about looking at the full stack of software platforms and services, is that it frees you from the mental constraint of the gallery, or the webpage. When you frame is an exhibition, everything looks like a kiosk. Same for good ole’ Web 1.0. The answer is usually a microsite or a web portal.
Monolithic systems break badly
Another issue that came up was the desire in some parts (often, but not always, administration) to create monolithic systems that will take care of everything. If you’ve been around long enough, you’ve probably run into vendors whose products will take care of all your digital needs. Their systems promise to be flexible, scalable, and easy to use (usually through the use of predefined templates). All your content will be seamlessly pushed to the destination of your choice, be it the exhibit hall or the Web. And though they may perform a lot of these functions, the reality is that they more often than not A) don’t deliver, and B) wind up becoming a straightjacket as the system ages, new systems join the ecosystem, and contracts/service agreements expire. As monolithic systems age, they don’t age gracefully, and when (not if) they break, they break badly.
Loose connections
That’s another place where designing systems and services that use the full stack is useful. The real power in looking at the entire data ecosystem is that a hierarchy of linked systems can be loosely connected through APIs, assuming your stack layers are built on and use APIs. A break in any one of these loose connections is unlikely to bring your whole ecosystem crashing down, and the fix to one piece need not require an overhaul of the whole system. A stack that relies on APIs can be much more friendly to new platforms being integrated into the stack. The downside is that creating and managing this kind of ecosystem requires staff resources that are different than the resources needed to maintain one monolithic system, or a series of unconnected ones. And museums tend to privilege depth of knowledge over breadth, even in digital roles.
To that end I tried to put together a possible statement of what PEM’s stack looks like/could look like. I invite you take a look. Add your own stack, too if you feel so inclined. Just make a new tab in the spreadsheet.

( It’s Katie Shelly )
LikeLike
Doh! I know that. How’d that happen? Can I blame autocorrect? Corrected with thanks.
LikeLike
This is a really interesting, idea, Ed. I added a tab to the spreadsheet that doesn’t necessarily refer specifically to the Blanton, but is more of an idealized model. I’ve been thinking a lot lately about Jim Barksdale’s concept of bundling and unbundling (check: https://hbr.org/2014/06/how-to-succeed-in-business-by-bundling-and-unbundling), and what it would look like to unbundle things we do in the museum and then put them back together in a way that makes more sense in Crazy Modern Times (for instance, to me it makes sense that the person who manages your collections API would also be your R&R person, since it’s the same job, just separated by modality). My tab on the spreadsheet reflects a really coarse attempt to do this.
LikeLike
Great way of parsing a pretty big broad stack, Koven! Thanks for sharing it! The Barksdale/Andreessen interview is also ace. Loads of goodness to digest there.
LikeLike
Better late than never? Just getting back in the office and giving this the attention it deserves. Added a tab to the spreadsheet:
https://docs.google.com/spreadsheets/d/1A4al28YCZnpSn4Dl8ew2v2cmffc1ViIcbCWxwE6AVq8/edit#gid=59044778
LikeLike
Thanks, Chad. Good food for thought!
LikeLike