One of the follow up conversations I had at MCN2015 was with Jeff Inscho about our Content session. It was a wide-ranging one, touching on repositories, the Museum full stack, and more. In my notes, I wrote the quote “Content – That Which is Lost” which was one of the definitions that came out of our session. It’s stuck with me since.
The “digital dark age” is a thing that lots of important people are worrying about.
Google boss warns of ‘forgotten century’ with email and photos at risk
Will Future Historians Consider These Days The Digital Dark Ages?
The digital black hole: will it delete your memories?
You get the idea. It’s a problem. I’ve been thinking a lot about digital ecosystems in museums, and how good they are at some things while being really terrible at others. Ironically, the thing that most digital ecosystems suck at most is preservation, followed closely by findability. This is a huge problem, one that will hobble not only us, but our successors and the posterity we supposedly hope to enrich by saving and interpreting all this stuff we steward. Here’s an illustrative example of what I’m talking about:

One of the last exhibitions I worked on at the Museum of Science was a renovation project. The New England Habitats hall is a diorama hall built in phases from the 1950s to the early 1960s. Some of the old-timers I worked with when I first started there in the ‘80s had worked on creating them, and they remain a central, unchanging feature of the museum. They were reinterpreted in the early ‘90s by the illustrious Betty Davidson, as part of her seminal research on making accessible, multisensory exhibits. The book that resulted, New Dimensions for Traditional Dioramas, is still relevant. By 2010, they were in need of another renovation, and I was charged with updating the content and exhibits. My first job was to understand what the original creators had been trying to do and how Betty et al had tried to modernize it. So, off to the Exhibits archives I went looking for what I could find.
For the ’90s renovation, that consisted mainly of Betty’s personal project file, some 3.5in floppies, and a couple of Syquest or Bernoulli cartridges that probably held large (for the time) graphics files. It was pretty skimpy, and missing all the email correspondence aside from those Betty printed out for some reason. A tremendous amount of sleuthing and DIY computer forensics allowed me to extract label copy from old Word and Pagemaker files.

For the original construction, back in the paper days, there were bulging file folders for each diorama, sometimes multiple folders (“Deer diorama” AND “Whitetail Deer”) with probably a couple of linear feet of files which covered everything: meeting notes, internal memos (some pretty intense), incoming and outgoing correspondence, plans, drafts of labels with edits. Along the way, I discovered things that had been lost over the years, like the fact that the dioramas were modeled on real locations in New England, not idealized environments as was more typical of the period. The photo research was all there, in piles of curling B&W prints. I could tell you exactly how much it cost to procure the beavers for the beaver diorama, because the trapper’s bill was there, complete with a description of how he dynamited their dam to get them and the lucky bonus that one of the beavers was pregnant, so the Museum got some bonus specimens. Different times. There was also the account of the poor staff member who had to drive a cooler full of rapidly thawing frozen beavers corpses from Vermont to the taxidermist’s studio in New York on one of the hottest days of the year that was obviously written solely for internal use. I could smell cigarette smoke clinging to papers that had sat on desks for too long. Everybody smoked then. A little more digging turned up originals of the transparencies used in the backlit labels, and other goodies from the stat camera. It was a treasure trove that let me climb inside my predecessors’ minds and understand what they were trying to do.
In the end, I knew more about what happened sixty years ago than what happened less than twenty years ago. And it was all because we hadn’t figured out how to save digital information in a way that made it findable and searchable, or anywhere near as easy to use as a manilla folder full of papers. This is not a problem exclusive to the MOS. When I first started at PEM and was snooping around to see what kind of 18th century firearms we had (as one does) I rapidly found out that the CMS’s records were pretty sparse in some areas, and if I really wanted to find out about older parts of the collection I should consult the card catalogue. The card catalogue. And I know that versions of this scenario play out at cultural organizations all over.
We have lost control of our stuff
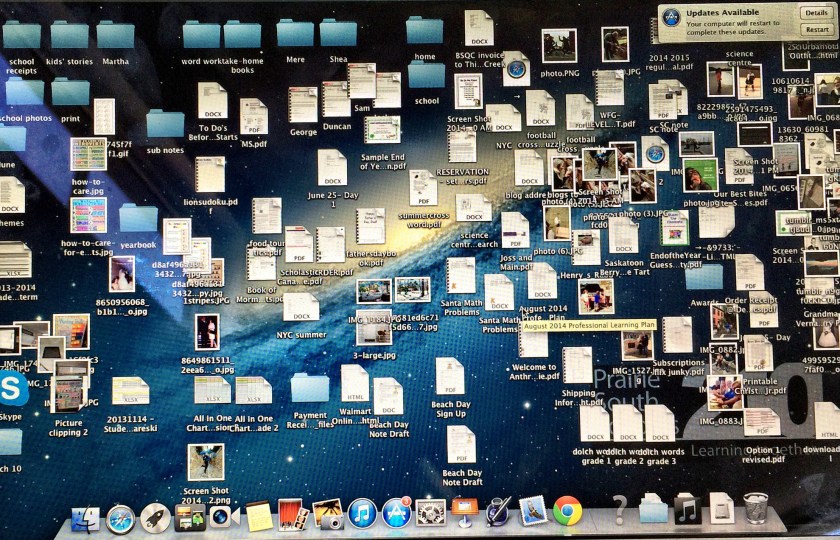
The proliferation of digital platforms and information has outpaced our ability to corral it and make it usefully findable. In place of the old hanging folder, a container that could hold anything you could cram into it, we now have information scattered across devices and platforms, mostly uninterchangeable and unsearchable. As a test case, I looked at a typical week’s worth of digital content and platforms I interacted with last week, and it consisted of:
- Emails, chats (corporate Gmail account)
- Google calendar events
- Texts (personal phone)
- Twitter (tweets, and DMs)
- MS Office docs (.doc, .docx, .xls, .xlsx, .ppt, .pptx)
- Google docs & sheets
- PDFs
- Video (various formats and FCP and AE projects)
- Audio files (.mp3, .wav, .aiff)
- Corporate network (five different servers, with varying access permissions)
- Basecamp messages, tasks, calendars (some turned into email, some not)
- Slack notifications
- Image files (All over the map: mostly .jpgs, many taken on the phone and uploaded to Dropbox, then spread across emails, work computer directories, network directories, Basecamp, and SM.
- Other SM content (Instagram posts, FB updates, and to a lesser extent LinkedIn and Foursquare)
In other words, it’s a mess. And I’ve already made clear my feeling about keyword searching in a previous post, so don’t get me started.
Please note that I am not advocating that we forsake digital technologies and return to paper. Are we clear on that? Good. Let’s move on…
What might we do?
The obvious solution is a repository, the museum equivalent of the “single source of truth” that software companies enshrine. But those sources only cover the codebase. If you were a future archaeologist trying to understand how 21st century software companies operated, you’d not find correspondence or financials in the repo. So how to create a digital version of the hanging folder that is as useful and possesses a generous enough interface to allow mere mortals to query it and find gold? That is a big question. Anybody out there having success?

Hi Ed,
Interesting post, and agree with you re “context/proximity” being very useful and interesting.
Two items I would like to point you to, so at least you have in your repertoire (not saying either fully addresses your goal for a number of reasons, but both interesting):
1) Data visualization environment under active development: VUE http://vue.tufts.edu/index.cfm. Open Source and free.
My experience with it has been exploring it as a manual design/documentation tool, not using its ability to semi-auto-aggregate incoming data feeds or large existing datasets or anything. (Short video here re latter here “Importing and visualizing a RSS feed in VUE” https://vue.tufts.edu/features/index.cfm.)
Has similar “flavor” in some ways to Visual Thesaurus, and is certainly interesting.
2) dtSearch. Great indexed search tool I use constantly and find invaluable. Will search through decades and terabytes of scattered (text-ish) files, over a network, literally in seconds. What makes it of particular interest (in addition to indexing both file names and file contents) is that it includes a “near” operator. In other words, a search of “(diorama w/10 meeting notes) and beaver” will find all instances of “diorama” with 10 words of the phrase “meeting notes” so long as “beaver” is unconditionally present in the document as well. So while it does not “show” context/proximity, it allows searching for same, which is an ENORMOUS improvement over pure boolean searches. Specifically, by adjusting the “n” in “w/n” one can quickly select the “radius (or radii) of proximity” one wants, and change from no matches to 10^10 matches as radius expands, and results are returned so fast that it is almost like using a dynamic radius slider. (But of course won’t help you find what you don’t know to look for…) http://www.dtsearch.com
David
LikeLike
Ed, thank you so much for this wonderful article. A good chunk of my last five (and happiest) years at the MOS was spent sorting, weeding and preserving the paper records of the Museums first fifty years. The filing cabinets had been pushed further and further away from human contact and at that time were in a leaky hallway leading to the garage. Your embrace of digital platforms while recognizing their inherent problems makes me happy.
LikeLike
Love the great stories you uncovered here. And the issue of discovery and preservation? This is why I decided to get an MLIS, because I saw museums could learn a lot from libraries in order to try and mitigate these problems as much as possible. So, I think one answer is to have great digital asset manager and/or archivist on staff who can help create workflows and processes so staff know what to save, where to save it, and how to describe it with meaningful metadata so it can be found by our future selves. A second step is just raising awareness of these issues internally. Another thought – at MCN this year I saw a presentation by MIA about a system they created for saving and sharing digital stuff internally called MetaMIA – it aggregates data from several repositories and makes it all searchable from one place. So you don’t even have to know which system (or shared drive – ugh) a document you need is on – it’s one search to join them all. Not sure it’s the holy grail, and I only know what I learned in that presentation, but it seemed really promising.
LikeLiked by 1 person
Thanks, Susan. Agree 100% about a DAMS mgr or archivist. Thanks for the MIA tip, too. I’ll have to poke Douglas for more details.
LikeLike
Thought provoking as always, thanks Ed.
Just a couple of days ago I was discussing with a colleague how bad we are at documenting exhibitions, particularly when you consider the fact that we’re in the business of keeping and documenting stuff. Exhibitions are products of their time and artefacts in themselves, but surprisingly little is kept for posterity (or sorted out in a way that would make sense to someone outside the project, and isn’t based on the idiosyncratic filing logic of a handful of individuals!).
I’m of the age whereby I’m young enough to have always worked with the vast majority of documents being electronic in origin, but old enough to remember when limited storage space had a big impact on what you could afford to keep. It meant the decisions of what was “worth keeping” were made without the benefit of a particularly long lens of hindsight. Change of file and media formats notwithstanding, perhaps we are in a better position now because we do once again have the luxury of keeping “everything”, even if it is haphazardly organised? Still not as immediate or as serendipitous as old fashioned paper though, I’ll grant you.
LikeLike